SN --> Dét N SP SP
Elles ne s'appliquent qu'au français.
Il est bien évident que les règles de réécriture
que nous avons découvertes ne s'appliquent qu'au français
puisque c'est à partir d'une étude de cette langue que nous
les avons formulées. Par contre, il est aussi évident que
les autres langues humaines (ou naturelles) doivent avoir recours à
des règles similaires mais différentes. Il serait donc plus
productif et plus intéressant de découvrir un système
qui permette de rendre compte non seulement de la forme des phrases du
français mais aussi de celles des autres langues (ou, au moins,
d'autres langues).
Elles sont trop puissantes.
Nos règles de réécriture ont aussi le défaut qu'elles permettent trop de possibilités qui n'existent sürement pas. C'est donc dire qu'elles "surgénèrent". Par exemple, on ne s'attend jamais à trouver des règles comme les suivantes dans une langue naturelle:
SN --> V SN
SP --> N SA
Le problème est qu'il y a un lien entre ce qui se trouve à
gauche de la flèche et ce qui se trouve à sa droite mais
ceci n'est pas exprimé dans la forme actuelle de nos règles.
Le besoin de niveaux intermédiaires.
Des chercheurs ont démontré que des niveaux intermédiaires sont nécessaires à l'intérieur des syntagmes de façon à expliquer des faits qui ne peuvent pas être expliqués avec les règles de réécriture que nous avons maintenant. Considérons par exemple les SN suivants:
Un étudiant de linguistique aux cheveux
longs
Un magazine de Paris sur la mode
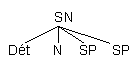
Ces SN ont une interprétation particulière, par exemple, "c'est un étudiant de linguistique et il a les cheveux longs". Ces SN contiennent deux SP. Nos règles de réécriture ne permettent qu'une structure, la suivante:
SN --> Dét N SP SP
Dans cette structure, les deux SP ont le même statut, i.e. ils sont tous deux dominés par SN. Nous avons donc, SP = SP. Le fait est que ces deux SP n'ont pas le même statut. Ceci peut être démontré en essayant de les permuter. S'ils sont égaux, cette permutation devrait nous donner un résultat grammatical et ayant la même interprétation que précédemment. Essayons:
*? Un étudiant aux cheveux longs de linguistique
Un magazine sur la mode de Paris
Le premier SN est bizarre, le deuxième est grammatical mais possède
une interprétation très différente de celle qu'il
avait dans sa forme originale. Il faudrait rendre compte de ceci mais nos
règles de réécriture ne nous le permettent pas.
Les rapports formels entre syntagmes.
Un examen plus rigoureux de nos règles de réécriture révèle que ce qui peut se retrouver à la droite de la flèche est souvent similaire d'un syntagme à l'autre. Par exemple:
SN --> N
SV --> V
SA --> A
SP --> P
Ceci se résume abstraitement:
SX --> X où X est une variable.
Suivant le même raisonnement, nous retrouvons:
SN --> N SP
SV --> V SN
SP --> P SN
SA --> A SP
Nous avons en fait affaire à la forme abstraite suivante :
SX --> X SY où X et Y sont des variables
De la même façon, nous pouvons aussi découvrir qu'il est toujours possible d'avoir :
SX --> Z X où X et Z sont des variables
Comme dans :
SN --> Dét N
SA --> SAdv A
Le problème est donc encore une fois que nos règles de réécriture ne rendent pas compte de ces faits. En fait, le problème véritable est qu'elles ne nous permettent pas de rendre compte de ces faits.